
Anthropic's Claude Certified Architect Exam (CCA-F): You Cannot Memorize Your Way Through the CCA-F
CCA-F Part 1: A 900 on the practice exam and a 670 on the live exam are the same person, the same week, the same knowledge. Here is the skill that swung more than 230 points between them, and how ...


Anyone can name the right pattern when the question hands it to them, but production never hands it to you; it hands you a system that is on fire and a clock that is running. That gap, between knowing what context windows are and feeling, at 2 a.m., that the agent is failing because the context blew past its budget, is the one skill no quiz score will ever prove you have.
In this article: You will learn why the CCA-F live exam and its practice exam measure different things, what the “60/40 problem” is and where prepared candidates actually lose points, the one principle (”code must, prompt should”) that two high scorers say unlocks the exam, and a ninety-second diagnostic that tells you exactly where to start. By the end you will know why your practice score is a floor to clear, not a forecast.
CCA-F Part 1: A 980 on the practice exam and a 744 on the live exam are the same person, the same week, the same knowledge. Here is the skill that swung more than 230 points between them, and how to build it.
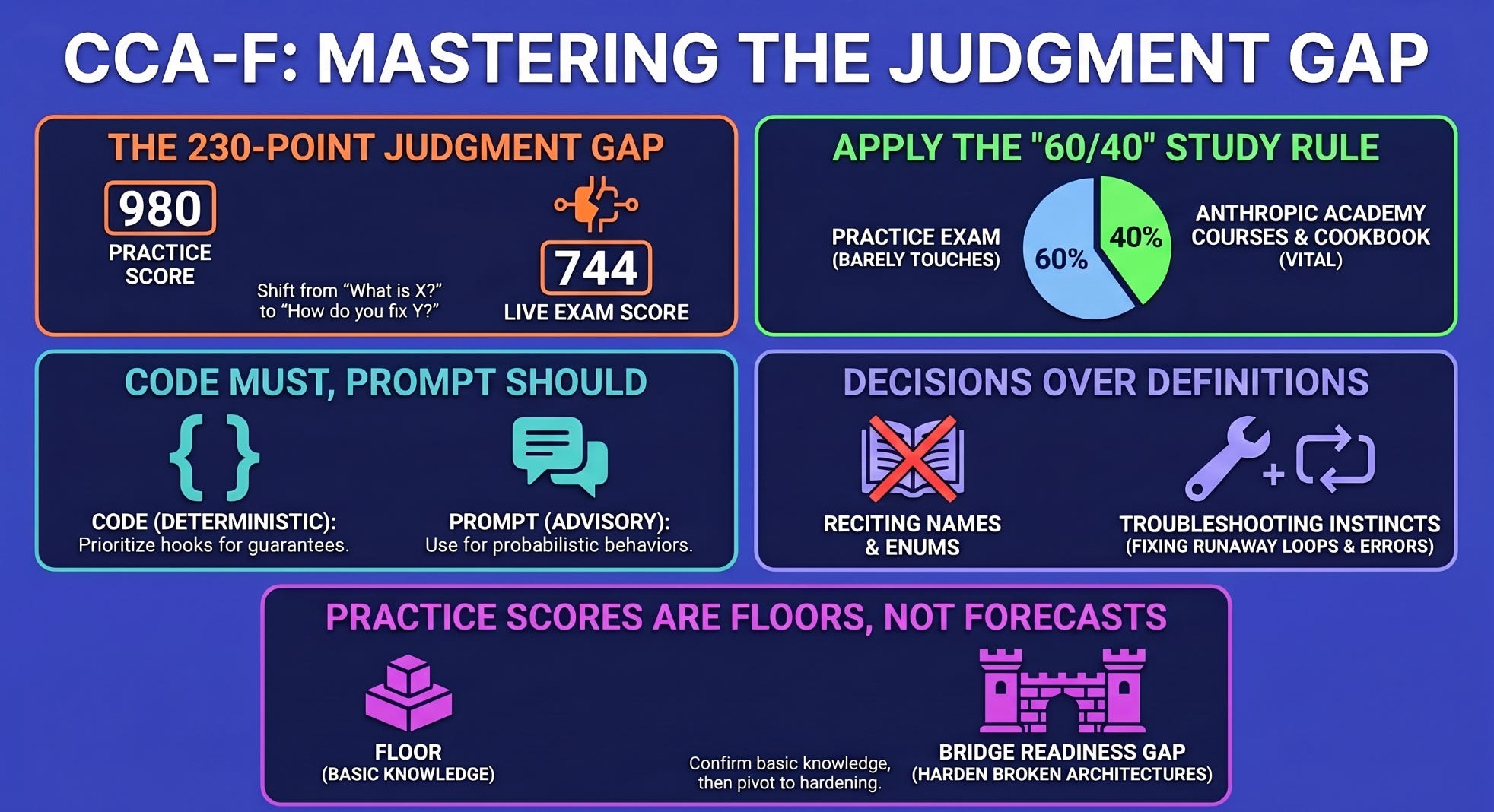
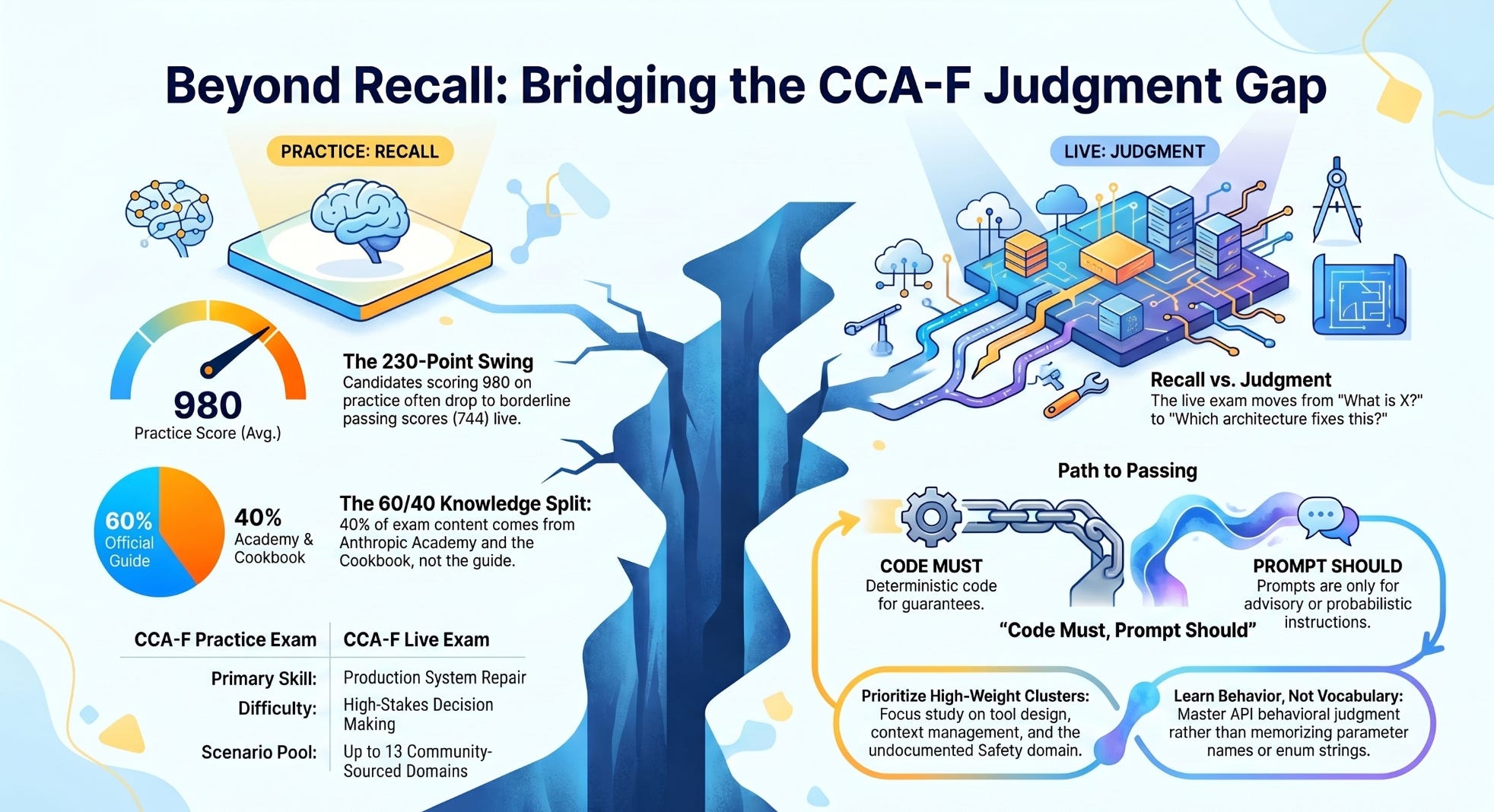
A real candidate scored 95 percent or higher on every home-grown question bank they built, then 980 out of 1000 on Anthropic’s official practice exam. They sat the live CCA-F exam and scored 744. That is a pass, barely, with a 24-point cushion over the 720 line. Keep in mind if you fail, you can’t take the test again for six months. The same person, the same week, the same knowledge, swung more than 230 points between the practice and the real thing.

That gap is the whole reason this guide exists. It is not a knowledge gap. It is a gap in what the two exams measure. The practice exam asks you to recognize a concept. The live exam drops you into a broken production system and asks you to repair it under a constraint you have to find for yourself. Those are different skills, and the practice exam quietly trains the wrong one.
If you have already cleared the practice exam, and you are either reading this after a failed attempt or bracing for one, you are in exactly the right place. Nothing here re-teaches you what stop_reason is. The work ahead is converting recall into judgment.

The exam at a glance
Here are the parameters, confirmed consistently across many first-hand accounts even though Anthropic keeps them behind the Skilljar login. Sixty multiple-choice questions, single answer each. One hundred twenty minutes. A scaled score from 100 to 1000, and you need 720 to pass. Around 99 US dollars per attempt. Closed book, with no Claude, no docs, and no other tabs, delivered online with webcam and screen-share proctoring. There is no guessing penalty, which means an unanswered question is scored exactly like a wrong one, so you answer every single question even if you are guessing.
The questions are not independent. They come in clusters hung off production scenarios. The official guide says four scenarios are drawn at random from a published pool of six, contributing roughly fifteen questions each. The six published scenarios are the Customer Support Resolution Agent, Code Generation with Claude Code, the Multi-Agent Research System, Developer Productivity with Claude, Claude Code for Continuous Integration, and Structured Data Extraction. Multiple candidates report the live pool is larger than six, credibly up to thirteen, though that larger figure is community-sourced and not confirmed by Anthropic.
A few operational realities are worth knowing before you sit. The proctoring software can glitch, including mid-exam sign-outs that eat your clock. Results turnaround is wildly variable, from about a day and a half to more than three weeks. And there are at least two documented cases of a borderline score being recalculated upward after the fact, so a narrow miss is not always final. None of this changes how you study. All of it changes how calmly you walk in.
The 60/40 problem in one page
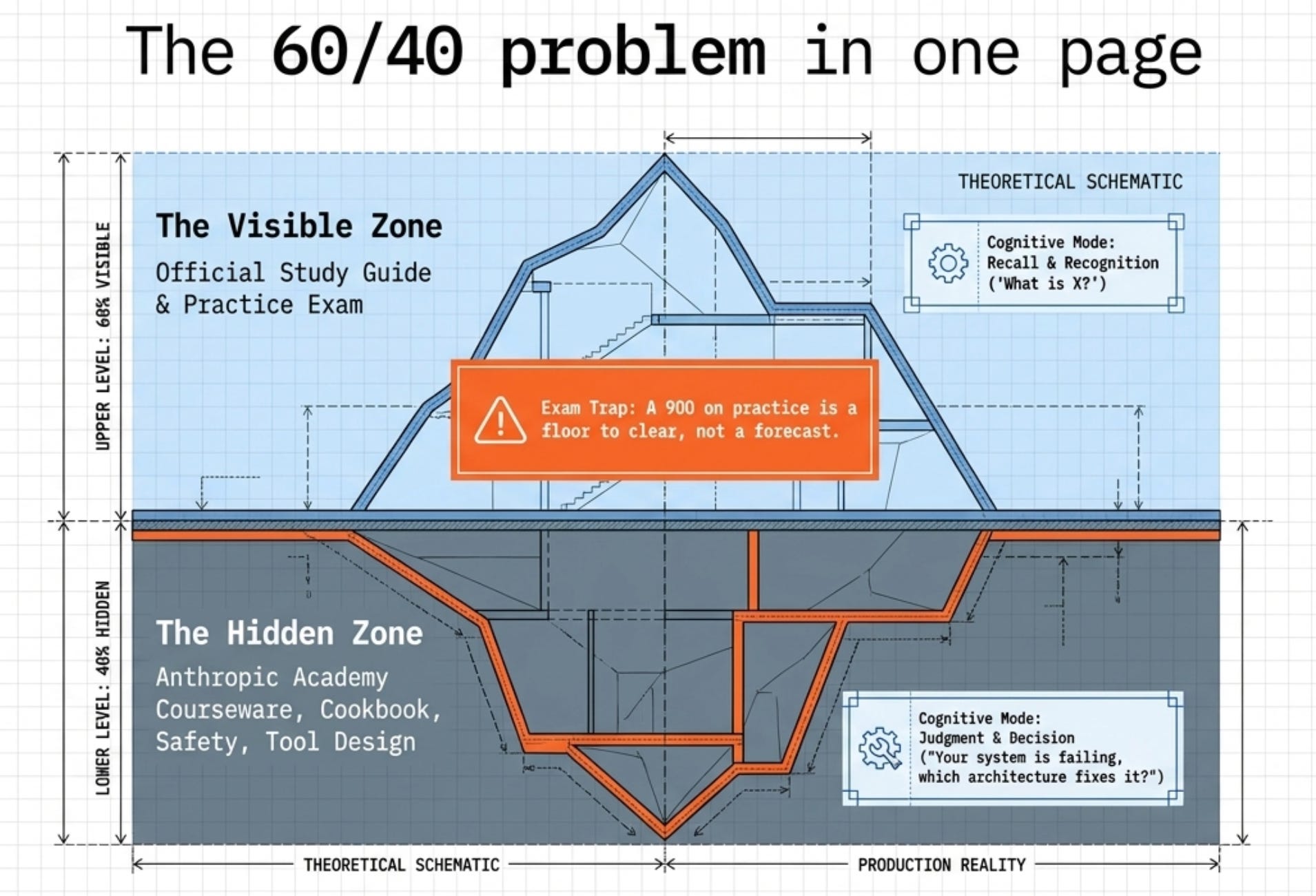
Think of the live exam as two stacked sources. Roughly 60 percent of it is covered by the official study guide plus the practice exam, the material you have probably already drilled. The other 40 percent comes from the courseware and the Claude Cookbooks, the free Anthropic Academy courses and the example notebooks that the practice exam barely touches. That 40 percent is where prepared candidates lose.

The split holds up three different ways in the research, but the more important finding is what drives it. The dominant gap is not a list of secret topics. It is a cognitive-mode mismatch. The practice exam reads as recall, asking “what is X?” or “which term describes Y?” The live exam reads as judgment, asking “your system is failing in this specific way, which of these four architectures fixes it?” with all four options plausible and the answer turning on one detail buried in the scenario. The same topic can sit in both exams and still be unrecognizable on the live one, because the framing changed from definition to decision.
There is a real topical gap too, and it clusters predictably. It lands hardest on structured output and tool design, with a deep secondary cluster in context management and a documented Safety and Responsible Deployment area that the five published domains do not even name. This guide weights your study time toward exactly those clusters. But the topical gap is the smaller problem. The framing is the bigger one.
Exam trap: trusting your practice score as a readiness signal. The practice exam is calibrated easier than the live exam, which is why a 180-point cushion exists in the first place. A 900 on practice is a floor to clear before you sit, not a forecast of your live score.

What “judgment, not recall” actually means
Every module in this guide teaches the same way, because the exam tests the same way. You see a broken architecture and the deterministic fix side by side, with a sentence before each scenario telling you what to watch for and a sentence after telling you which answer wins and why the tempting ones lose. The scenario never carries the lesson alone. The principle comes first, in words, and the scenario proves it.
One principle runs underneath all of it, and two high scorers independently call it the thing that unlocks the exam. Code must, prompt should. Anything that has to be guaranteed gets enforced in code: a hook, a gate, or a schema. Anything advisory lives in the prompt. When a question offers you “strengthen the system prompt” against “add a deterministic check,” and the requirement is a guarantee, the prompt answer is the trap nearly every time. A prompt instruction is probabilistic. A hook is not.

Beyond the practice exam: the live exam is not an API documentation test. It does not reward you for reciting parameter names or exact enum strings, and one named passer reports almost no
stop_reasonenumeration questions at all. What it rewards is API behavioral judgment: knowing when rolling-window context helps, when the Message Batches API is the wrong call despite being cheaper, and how a stateless session forces your application to own continuity. Learn the behavior, not the vocabulary.
Meet the agent you are going to fix
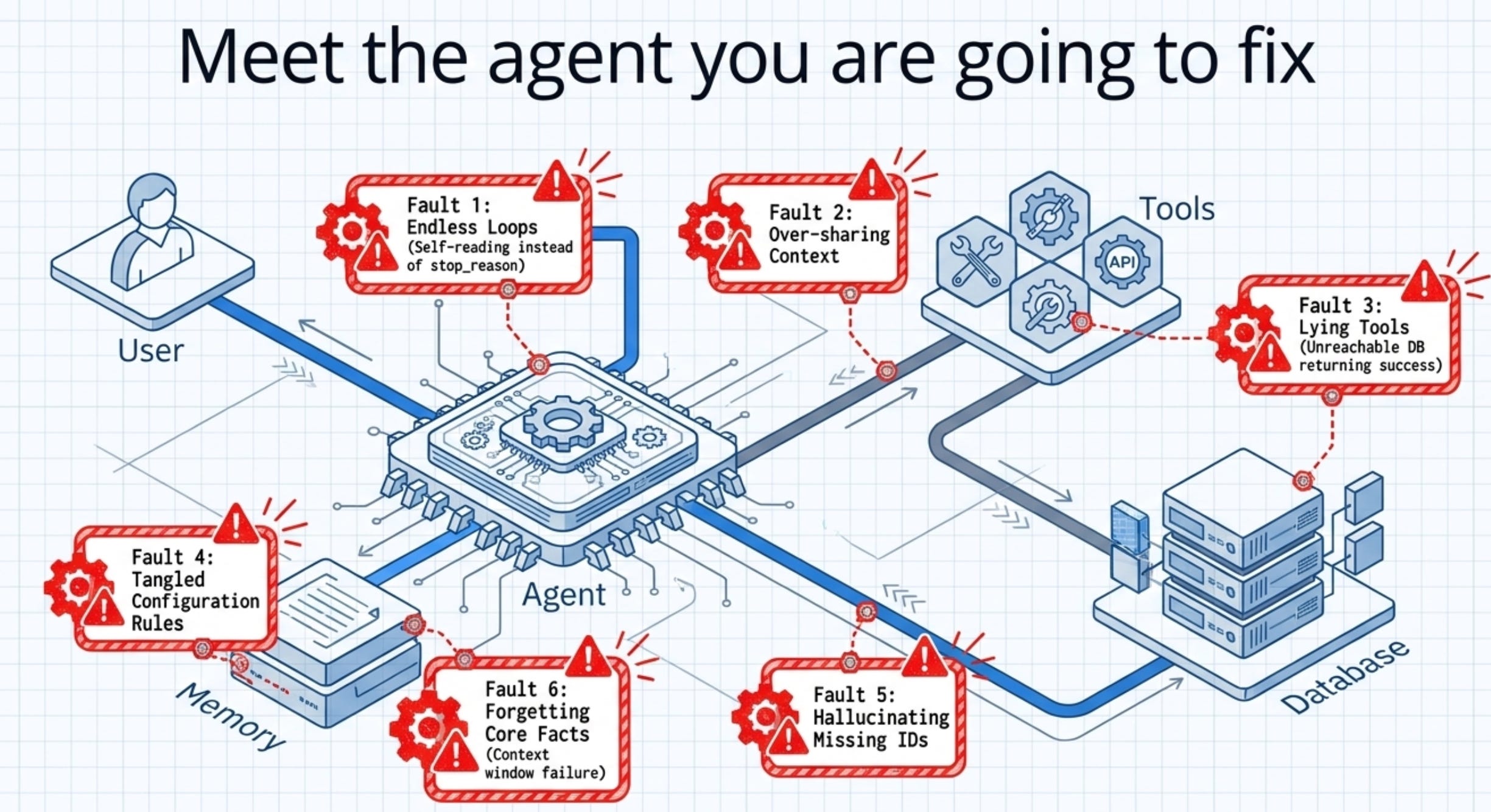
You will not study these domains as six disconnected topics. You will harden one architecture across the whole guide: a production customer-support agent that issues refunds, looks up orders, and escalates to humans. Call it the runaway refund agent, because it ships deliberately broken, one failure class per domain.
It loops forever because it decides it is finished by reading its own output for the words “all done” instead of checking stop_reason. It over-shares, handing every subagent the full conversation history instead of just what each one needs. Its tools lie, returning a cheerful success when the order database was actually unreachable. Its Claude Code configuration is a tangle of conflicting rules across three files. Its structured output hallucinates a customer ID rather than admitting the field was missing. It forgets the most important fact in a long conversation because that fact sat in the middle of the context window. And it will happily issue a 500 dollar refund because a line of injected text in a product review told it to.

Each module repairs one of these without undoing the earlier fixes. By the end you will have reasoned through the exact failure modes the exam baits, on one system you understand cold rather than six you half-remember.
In production: this is also just how you would actually debug an agent. Stop the runaway loop, make the tools tell the truth, untangle the configuration, stop the hallucinated output, fix the memory, and gate the unsafe actions. The exam rewards the same instinct a good on-call engineer has, which is why building real systems beats drilling flashcards.

A ninety-second readiness diagnostic
Answer these honestly in your head. Each one is paraphrased and original, never a live question, and each maps a wrong or unsure answer to the module that fixes it. If you are confident on all six, you are closer than most. If you stall on any, you have your starting point.
An agent keeps calling tools in an endless loop. Is the reliable fix to cap the iteration count, to scan the model’s text for a completion phrase, or to terminate on the response
stop_reason? If you reached for the iteration cap or the text scan, start with Module 1.Your order-lookup tool cannot reach the database. Should it return an empty result, return a success with no rows, or return an explicit error the model can act on? If “empty result” felt fine, start with Module 2.
Two rules about commit style live in your project CLAUDE.md and a deeper path-scoped file, and they conflict. Does the deeper rule silently win, does the higher rule win, or do the levels combine and get interpreted together? If you assumed a clean override either way, start with Module 3.
An extraction model is asked for a customer ID that the source document never contained. Should the schema let the model omit the field, invent a plausible ID, or return an explicit null or an “unclear” value? If omission or invention sounded acceptable, start with Module 4.
A long support conversation loses a critical fact that was established many turns ago. Is the fix to send a longer history, to assume the API remembers the earlier turn, or to restructure the context so key facts sit at the edges and get extracted during summarization? If you leaned on the API remembering anything, start with Module 5.
Your chatbot just took a costly action because a product review it was reading contained an instruction telling it to. Is the responsible fix to add a disclaimer, to strengthen the system prompt, or to isolate untrusted input and gate the privileged action in code? If a prompt-level answer tempted you, start with Module 6, the one the five published domains never warn you about.

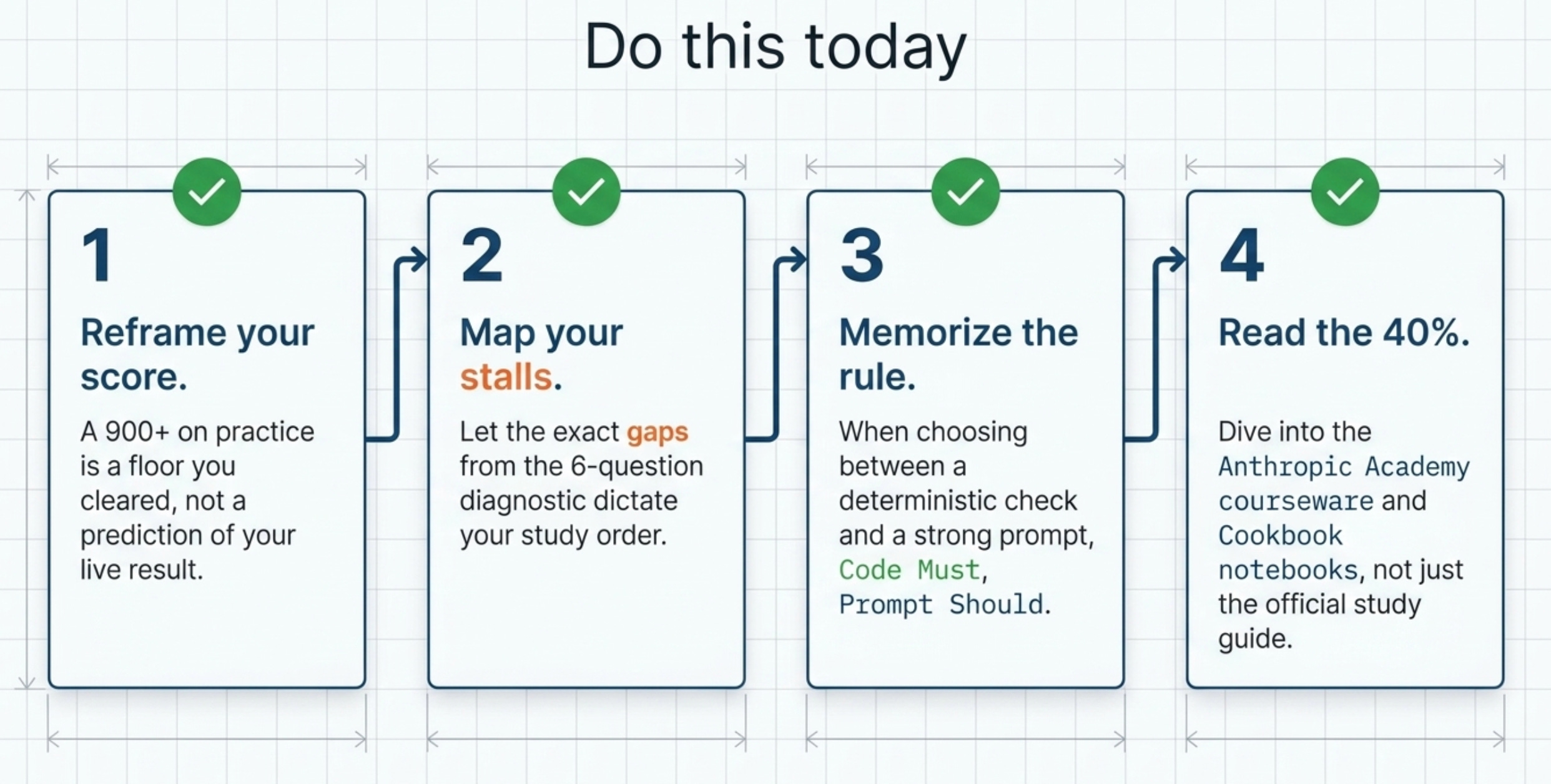
Do this today
Stop treating your practice score as a forecast. Reframe a 900-plus on practice as a floor you cleared, not a prediction of your live result.
Run the six-question diagnostic above and write down every stall. Each stall names the exact module to study first, so let the gaps set your order.
Memorize one principle before anything else: code must, prompt should. When two answers compete and one is a deterministic check while the other strengthens a prompt, the deterministic one wins whenever the requirement is a guarantee.
Reread the Anthropic Academy courseware and the Cookbook notebooks, not just the study guide. That 40 percent of material is where prepared candidates lose points.
Practice converting definitions into decisions. For each concept you know by name, ask yourself which production failure it fixes and which plausible-looking option it rules out.
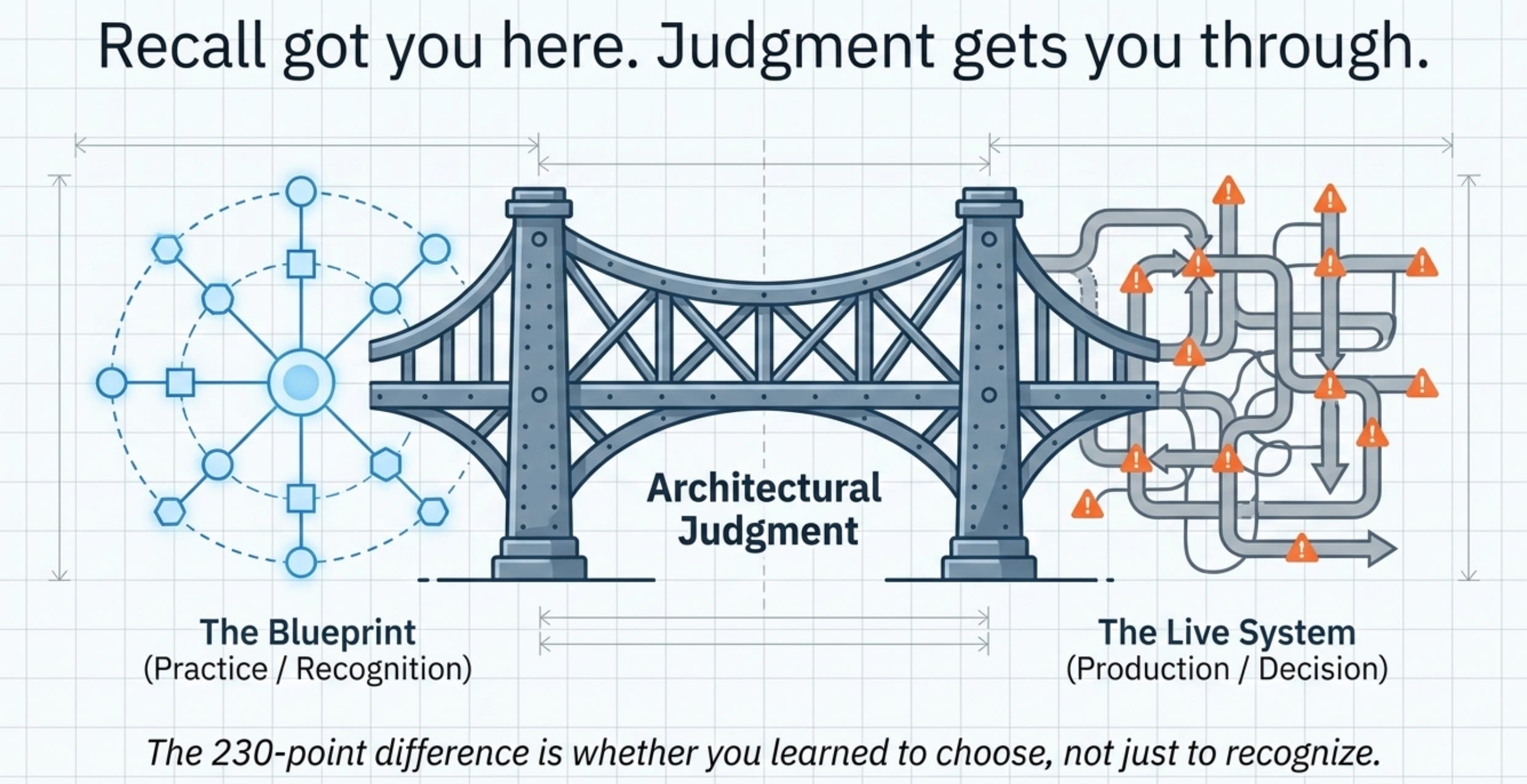
Recall got you here. Judgment gets you through.
The practice exam gave you the blueprint. It did not give you the judgment, and judgment is what the 40 percent and the 230-point swing are made of. The rest of this guide is that judgment, built one broken system at a time.
You start where the exam puts the most weight and where passers score highest, which makes it the best place to build momentum: agentic architecture and orchestration. The first thing to fix is the loop that never stops. A 900 and a 670 could be the same person; the difference is whether that person learned to choose, not just to recognize.
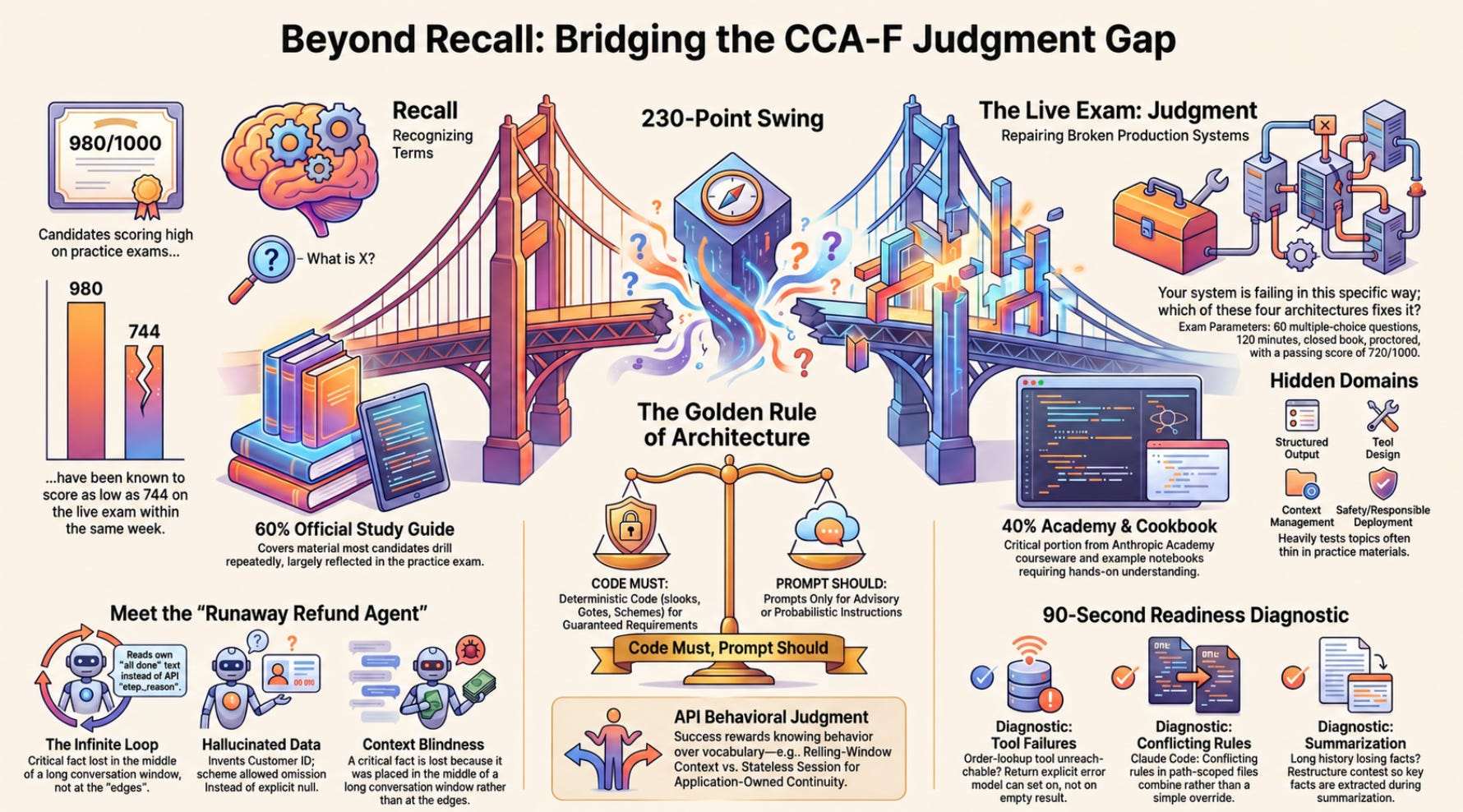
This is Part 1 of “Passing the CCA-F: From Recall to Judgment,” a twelve-part guide that turns candidates who can ace the practice exam into candidates who pass the live CCA-F by converting recall into production judgment.



About the Author — Claude Certified Architect
Rick Hightower helps companies become AI-first through practical mentoring, executive and team training, and custom AI solution development. A former Senior Distinguished Engineer at a Fortune 100 company, Rick focused on bringing ML and AI insights into real front-line business applications.
Rick is a Claude Certified Architect, AI systems practitioner, builder of production multi-agent systems, creator of Skilz, and author of an upcoming Manning book on Harness Engineering.
Ready to make your company AI-first? Connect with Rick on LinkedIn, Substack or Medium, book him to speak or train your team, or visit Spillwave to explore mentoring, training, and custom AI solutions for your organization. Check out Rick Hightower’s SpeakerHub.